Company • May 1, 2026
10X Cost Reduction with Spring Data on EloqKV
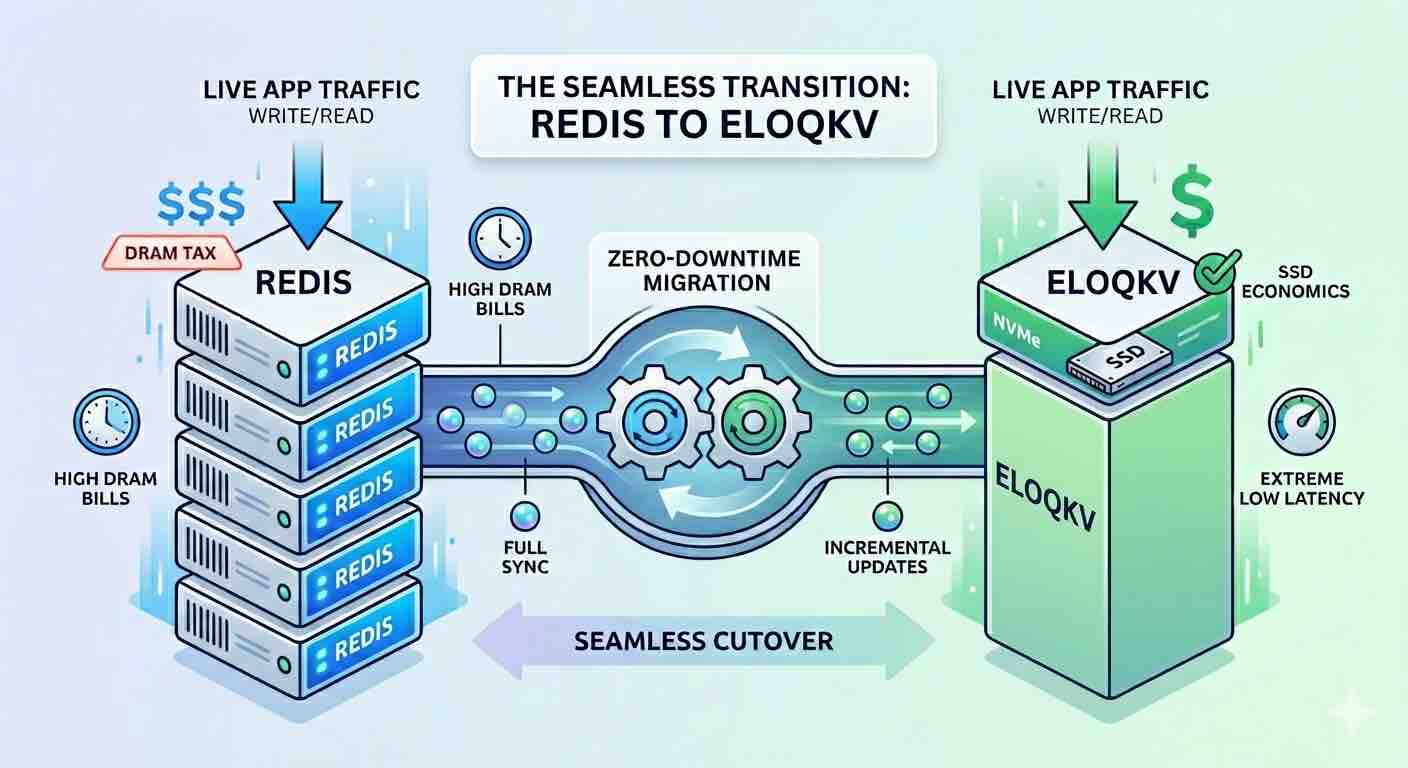
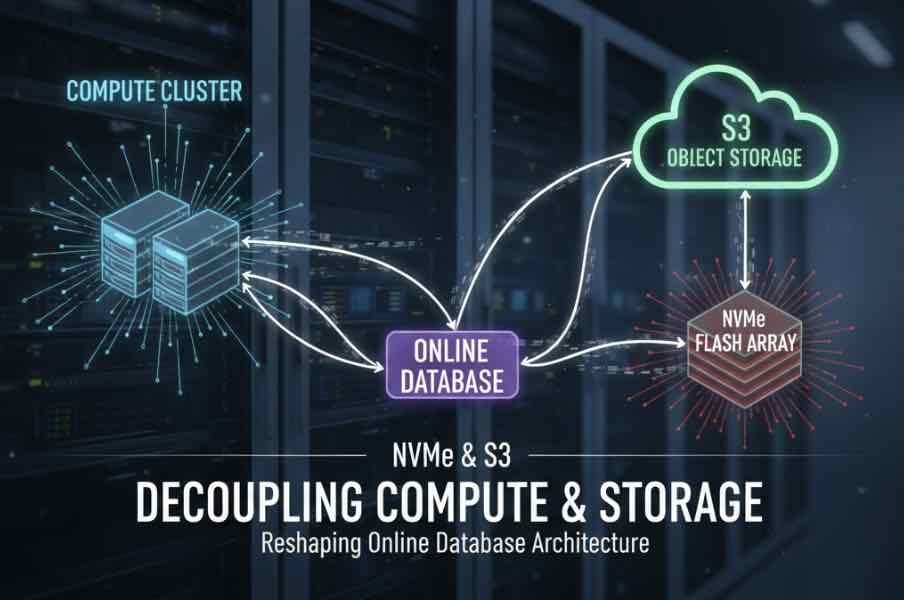
We benchmarked the same Spring Boot caching layer against Redis and EloqKV — with zero code changes. The throughput is comparable. The infrastructure bill is not.
We benchmarked the same Spring Boot caching layer against Redis and EloqKV — with zero code changes. The throughput is comparable. The infrastructure bill is not.