Building a Data Foundation for Agentic AI Applications

We have recently open sourced our three products: EloqKV, EloqSQL, and EloqDoc. These offerings reflect our commitment to addressing the evolving demands of modern data infrastructure, particularly as we enter an era dominated by powerful, autonomous AI systems.
LLM-powered Artificial Intelligence (AI) applications are driving transformative changes across industries, from healthcare to finance and beyond. We are rapidly entering the Agentic Application Age, an era where autonomous, AI-driven agents not only assist but actively make decisions, manage tasks, and optimize outcomes independently.
However, the backbone of these applications—the data infrastructure—faces immense challenges in scalability, consistency, and performance. In this post, we explore the critical limitations of current solutions and introduce EloqData’s innovative approach specifically designed to address these challenges. We also share our vision for an AI-native database, purpose-built to empower the Agentic Application Age, paving the way for smarter, more autonomous, and responsive AI applications in the future.

Why We Need New Data Infra in the AI Age
AI applications are inherently data-intensive. To build such an application, developers must design a system capable of storing, processing, and retrieving diverse data types to fuel machine learning models, ensure real-time decision-making, and support continuous improvement. A typical AI application integrates several components:
- Data Ingestion and Preprocessing: Collect raw data from various sources and transform it into formats suitable for analysis.
- Model Training and Fine-Tuning: Train AI models on structured and unstructured data to improve performance on specific tasks.
- Inference and Deployment: Use trained models to make predictions or automate workflows.
- Feedback Loops: Capture user interactions and outcomes to retrain models for improved accuracy and adaptability.
AI applications deal with diverse data types, each with specific storage and retrieval requirements:
- Structured Data: Typically stored in relational databases for tasks requiring tabular representations (e.g., user profiles, transaction histories).
- Unstructured Data: Includes text, images, and videos, stored in document databases or object storage systems.
- Embeddings: Vector representations of unstructured data for similarity search, often stored in vector databases.
- Graphs: Relationships between entities (e.g., social networks, knowledge graphs), stored in graph databases.
- Metadata: Information about data objects, stored in SQL or document databases for indexing and retrieval.
Challenges
With platforms like LangChain and LlamaIndex, developers can seamlessly integrate multiple databases into AI workflows, enabling efficient storage and retrieval of multi-modal data. However, this approach often causes several challenges.
The first challenge is management complexity. AI applications typically need multiple databases to manage different data types. Each database comes from a different vendor, requires specialized skill sets, and has unique backup and failure recovery procedures. Backup strategies and failure recovery operations vary significantly between database systems, complicating overall infrastructure management. The additional effort required to maintain consistent backup routines, implement disaster recovery protocols, and ensure high availability across diverse database environments significantly increases operational complexity.
The second challenge is related to flexibility and agility. Modern databases are often designed to handle a specific type of workload under a specific range of performance envelopes. For example, Redis is designed to address latency issues, by sacrificing persistency, while PostgreSQL guarantees durability by trading-off scalability. Unfortunately, the landscape of AI applications is still rapidly changing. There is simply no “standard architecture” to handle typical AI application needs. Choosing a simple data architecture might involve a total revamp of the entire data pipeline as the application evolves.
The third challenge, which might be much more fundamental, is the difficulty of ensuring data consistency across multiple databases. AI applications often require combining data from diverse sources, which introduces transactional challenges. Databases traditionally provides ACID transactional semantics to ease the complexity of application development. This valuable property is lost when a query needs to be carried out by multiple databases. Without the ACID property, application developers are left to deal with the data consistency issues in application code, which is often error prone.
Consider building a simple Retrieval-Augmented Generation (RAG) application to handle, say, financial reports of the public companies. RAG requires a document to be chunked and vectors of each chunk to be added to a vector database, while the document itself stored in a document DB. If the document is added while the insertion of the vectors failed, we may not be able to retrieve the document. On the other hand, if the vectors are added while the document failed to be inserted, we may get “broken links”. After a while, the developers may feel that knowledge graph of the companies might be a helpful source of information, and GraphRAG might increase the recall quality. Therefore, we may need to add a graph database to the pipeline. Soon, real-time news and social media might be interesting data sources, so we need to quickly ingest these feeds. Shall we use a streaming platform? As one can imagine, the data pipeline quickly grows out of hand. How to guarantee consistent user experience when data is constantly being added to multiple complicated and independent database systems? How to make joint queries when the databases are constantly out of sync?
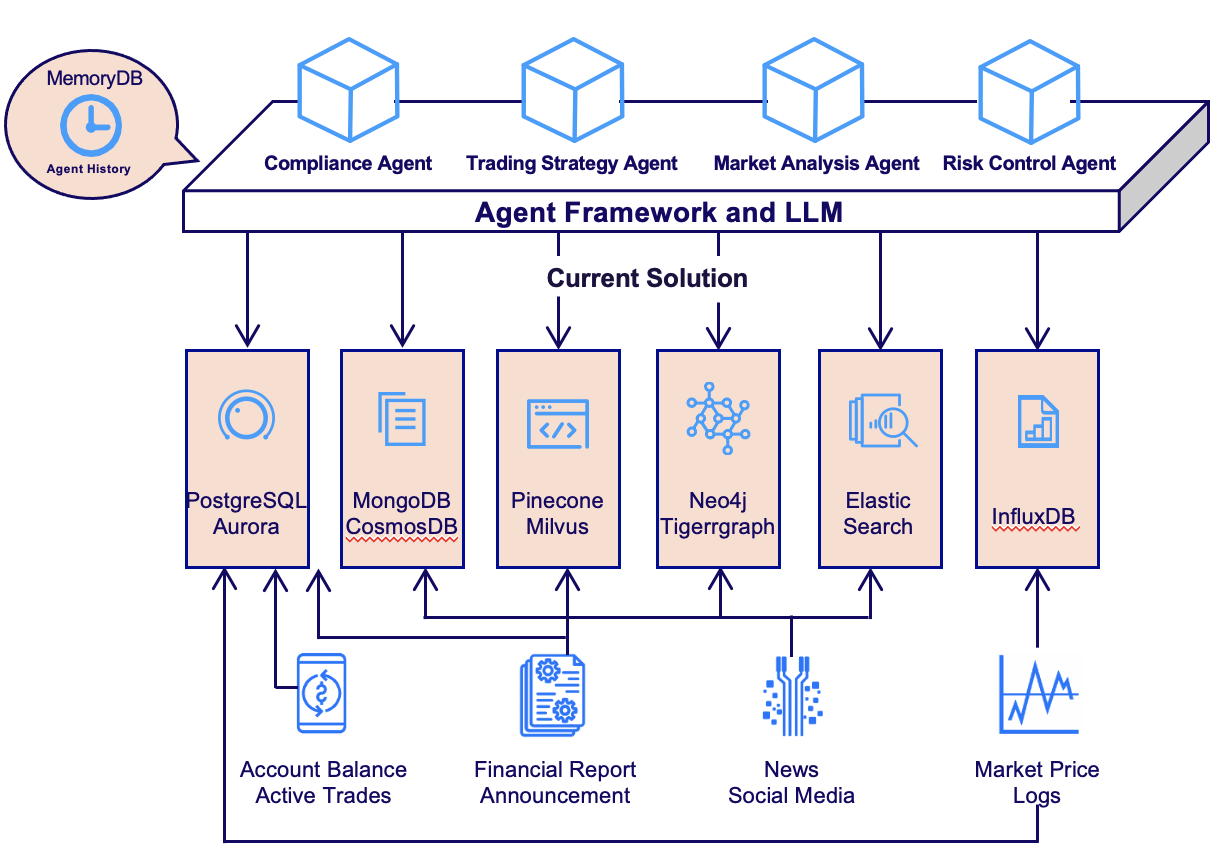
How EloqData can Help
Some argue that eventual consistency is sufficient for AI applications. While this is true in certain scenarios, we believe a one-stop solution with full ACID transactions and lower costs is not only desirable but essential.
Why Eventual Consistency Falls Short
- Operational Complexity: Managing retries, failures, and inconsistencies in an eventual consistency model adds significant development and maintenance burden.
- Scalability Risks: As AI applications grow, maintaining consistency across multiple databases becomes increasingly challenging.
The Promise of a Unified Solution
EloqData is redefining data infrastructure for AI applications with a one-stop solution ConvergedDB, that offers high performance, scalability, and full ACID transactions. This breakthrough eliminates the need for complex middleware like Kafka and allows developers to focus on building applications rather than managing infrastructure. At the heart of this solution is our innovative Data Substrate architecture.
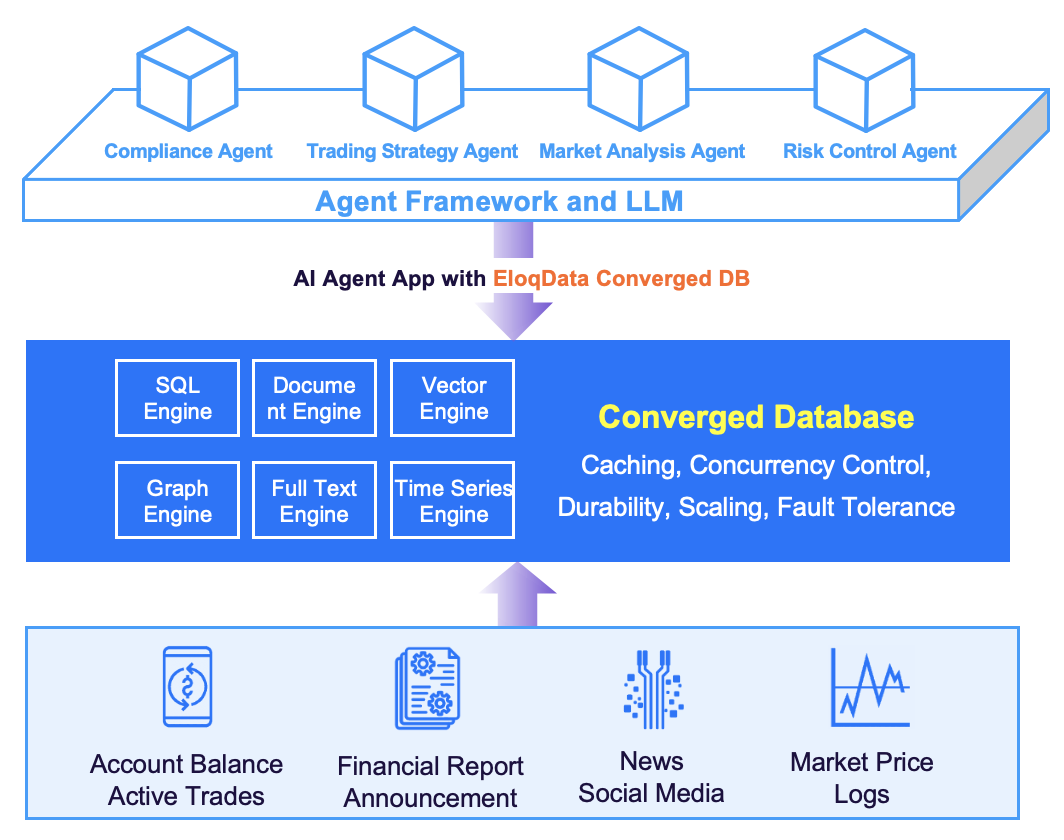
Looking into the Future
While current RAG implementations may not demand strong ACID guarantees, the future of AI applications points toward more complex, collaborative agent architectures. Imagine a network of AI agents collaborating on tasks ranging from financial transactions to regulatory compliance. These scenarios will undoubtedly require strong ACID properties to ensure consistency and reliability.
Future-Proof Your Infrastructure with EloqData
By choosing EloqData from day one, organizations can:
- Eliminate Scalability Concerns: EloqData’s architecture ensures seamless scalability, whether your business grows vertically or horizontally.
- Ensure Consistency: As multi-agent architectures become the norm, EloqData’s cross-model transactional guarantees will prove invaluable.
- Maintain High Performance: With no performance degradation, EloqData delivers a robust solution for the most demanding AI applications.
The future of AI applications requires data infrastructure that is scalable, consistent, and performant. EloqData’s one-stop multi-model database ConvergedDB, powered by its Data Substrate architecture, delivers on all three fronts, enabling developers to focus on innovation rather than infrastructure.
ConvergedDB is launching soon! Your feedback is greatly appreciated—stay tuned!