How NVMe and S3 Reshape Decoupling of Compute and Storage for Online Databases

Cloud native databases are designed from the ground up to embrace core cloud principles: distributed architecture, automatic scalability, high availability, and elasticity. A prominent example is Amazon Aurora, which established the prevailing paradigm for online databases by championing the decoupling of compute and storage. This architecture allows the compute layer (responsible for query and transaction processing) and the storage layer (handling data persistence) to scale independently. As a result, database users benefit from granular resource allocation, cost efficiency through pay-per-use pricing, flexibility in hardware choices, and improved resilience by isolating persistent data from ephemeral compute instances.
In this blog post, we re-examine this decoupled architecture through the lens of cloud storage mediums. We argue that this prevailing model is at a turning point, poised to be reshaped by the emerging synergy between instance-level, volatile NVMe and highly durable object storage.
Separate Storage Nodes
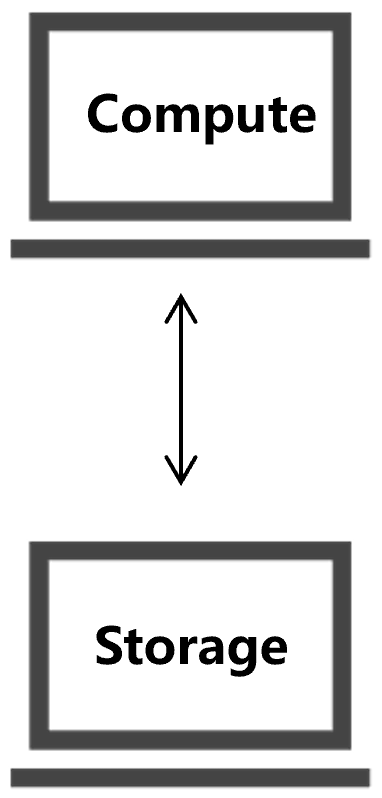
The Aurora's design decouples a database into a stateless compute node and stateful, distributed storage nodes. The compute node executes queries and transactions, while storage nodes manage the transaction logs (WAL) and data pages. Internally, storage nodes apply log records to data pages, perform log truncation, and serve read requests for data absent from the compute node's buffer pool.
The influence of the Aurora’s decoupled architecture is unmistakable across the cloud database landscape. Successors like GCP AlloyDB and Azure SQL Database Hyperscale have all embraced similar architectures. The trend continues in open-source projects like NeonDB, which implements the decoupling architecture through its pageservers (data pages) and safekeepers (WALs).
The trend also extends to distributed databases like CockroachDB, TiDB, and YugabyteDB. Although they were originally architected as shared-nothing systems, it has become a common and recommended practice to deploy them on two sets of servers: one cluster for stateless compute and the other for stateful storage. This operational separation further refines the principle of independent scaling and management.
In essence, one could argue that compute-storage decoupling serves as a foundational pillar for cloud-native online databases, which rely on one or more separate storage nodes.
The Landscape of Cloud Storage Mediums
It is a common misconception to view cloud storage as merely an extension of on-premises solutions. In fact, cloud platforms offer a diverse spectrum of storage mediums, each with performance and cost characteristics that differ drastically from traditional models. The three most common tiers in the cloud are instance-local storage (e.g., NVMe), network-attached block storage (e.g., Amazon EBS), and object storage (e.g., Amazon S3).
Block-level storage is a cloud service that emulates network-attached hard drives. As a resource provisioned and billed independently from VMs, it guarantees full data durability beyond the lifecycle of any attached VM. The combination of familiarity and resilience has made it the de facto storage medium for online databases.
Instance-level storage is temporary, high-performance block storage that resides directly on a VM's physical host. Physical proximity enables extremely low-latency access. Specifically, instance-level NVMe have pushed performance to unprecedented levels: up to 2 million IOPS. However, this raw speed comes with a critical trade-off: the storage is ephemeral, meaning all data is lost if the instance is stopped, terminated, or experiences a hardware failure.
Block-level and instance-level storage thus represent a fundamental trade-off for storing data in the cloud. Block storage guarantees durability at a steep premium, whereas instance storage delivers superior performance and lower cost but sacrifices all data persistence.
To understand the stark performance-price difference between instance-level NVMe and block-level storage, let's examine a concrete example from Amazon. Amazon EBS io2 is a premium block storage solution offering up to 256K IOPS. Provisioning an io2 volume with 150K IOPS and 1 TB capacity costs approximately $6,000 per month. By contrast, an Amazon storage-optimized instance i8g.xlarge provides comparable performance with 150K IOPS and 937 GB of local NVMe storage. This instance features 4 vCPUs and 32 GB of memory, and yet costs only $247 per month. When we subtract the cost of compute resources, i.e., $170 for an equivalent r8g.xlarge instance with identical CPU and memory but no local storage, the net cost of the high-performance NVMe storage becomes almost negligible compared to the premium EBS solution.
Apart from block and instance storage, object storage is a scalable storage service for organizing data as objects in buckets. It excels at handling unlimited data with high durability (e.g., 99.999999999%) at a very low cost, often cheaper than traditional on-premises storage. However, its access latency is unpredictable and can be as high as hundreds of milliseconds. This performance profile has historically precluded its use as the default storage for online databases.
NVMe + Object Storage
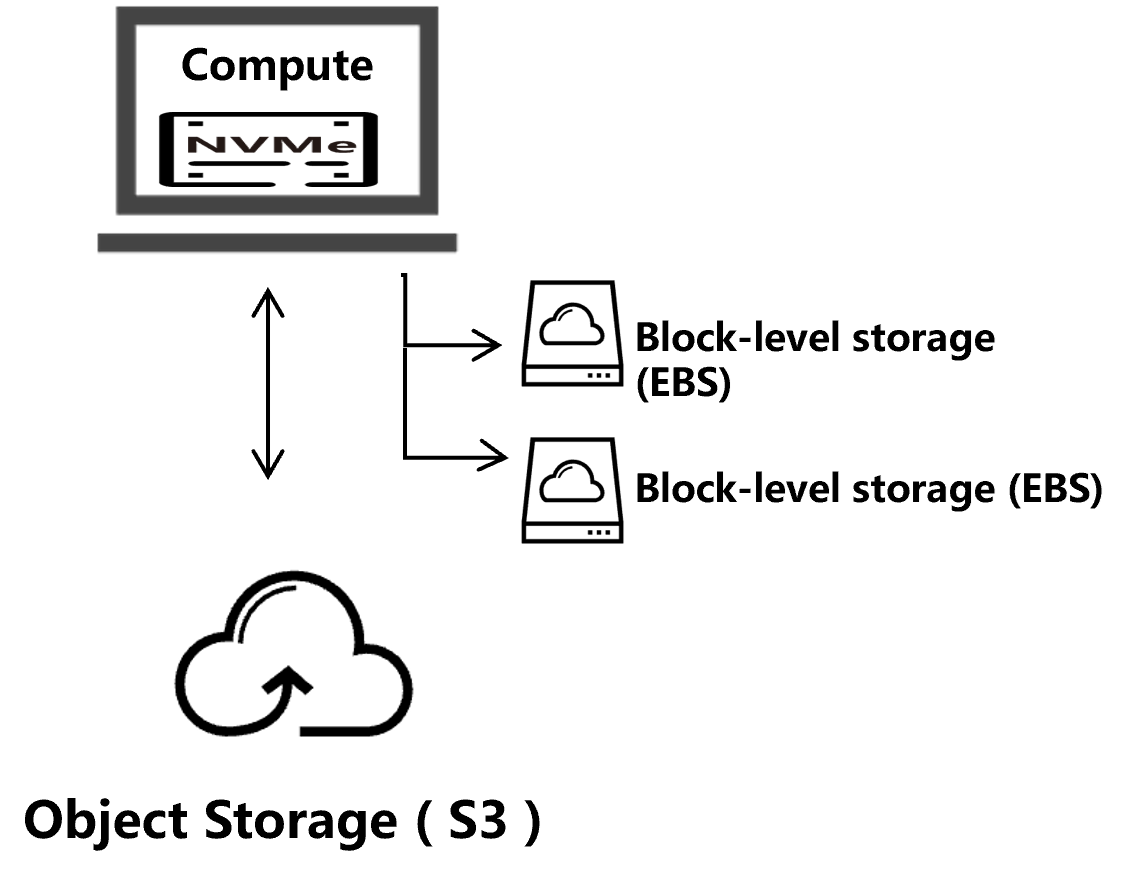
Given the landscape of cloud storage, a growing consensus recognizes that block-level storage is ill-suited for primary storage of online databases, being both prohibitively expensive and slow. Instead, a combination of instance-level NVMe and object storage is emerging as a superior architectural pattern.
- Write path: Data modifications are first committed to local NVMe storage and then uploaded to object storage.
- Read path: Reads that result in in-memory cache misses are served directly from the local NVMe, ensuring low-latency access and high I/O throughput.
- Stateless compute: VMs can be freely stopped or migrated. A new instance simply reconnects to object storage and incrementally downloads data files to its local NVMe.
In this design, NVMe delivers exceptional performance at a fraction of the cost of block-level storage, while object storage provides the ultimate guarantee of data durability.
A legitimate concern with the combination is the potential for unpredictable latency. This could occur if an online query needs to download from object storage a data file not available on local NVMe, which has reached its capacity limit.
However, we contend that such scenarios should be rare for two reasons. First, the scale of local NVMe capacity available in the cloud is substantial. Consider Amazon's storage-optimized i8g instances: a 64-vCPU VM provides 15 TB of local NVMe storage. Second, if a dataset grows beyond the capacity of a single node, the storage engine should be scaled out horizontally across multiple VMs. A conscious decision to operate with smaller local storage than the total dataset size should only be made when the application's access pattern exhibits strong locality (e.g., focusing on recent data) and can tolerate occasional high-latency access to colder, historical data archived in object storage.
A second common concern regarding object storage is high write latency. However, this is effectively mitigated by a well-designed database architecture that leverages a transaction log. The transaction log absorbs all writes on the critical path, ensuring low-latency commitments. The actual data writes to object storage are then deferred to asynchronous, background checkpointing processes.
Since checkpointing is a throughput-oriented, background task, it is inherently tolerant of higher latency. Therefore, the performance characteristics of object storage writes have a minimal impact on online queries.
With NVMe and object storage serving as the storage mediums for database storage engines, block-level storage finds a new role in managing the transaction log. The transaction log demands high write throughput, moderate IOPS (which is easily satisfied by the batched, append-only write pattern), and relatively low capacity due to continuous log truncation. Crucially, it must also guarantee 100% durability the moment a query commits, while maintaining low write latency. These specific requirements align well with the performance and durability profile of block-level storage, allowing databases to leverage it for the transaction log at a remarkably low cost. For instance, an Amazon EBS gp3 volume providing 3,000 IOPS, 500 MB/s of throughput, and 100 GB of capacity can be provisioned for approximately $20 per month.
New Shapes of Decoupling
The combination of instance-level NVMe and object storage will redefine the architecture of compute-storage decoupling. In this new paradigm, object storage serves as the decoupled storage layer, which offers unlimited capacity and permanent durability. Meanwhile, instance-level NVMe acts as a local storage cache, in addition to main memory, and becomes an integral part of the compute layer. Within this framework, block-level storage finds its optimal role as a dedicated, cost-effective medium for hosting the transaction log, which is attached directly to compute nodes where low-latency writes are critical.
Of course, the established decoupled architecture can be augmented by equipping storage nodes with local NVMe, preserving the original benefits of independent scaling while enhancing storage performance. However, we argue that the value of such an enhancement is diminished in many scenarios.
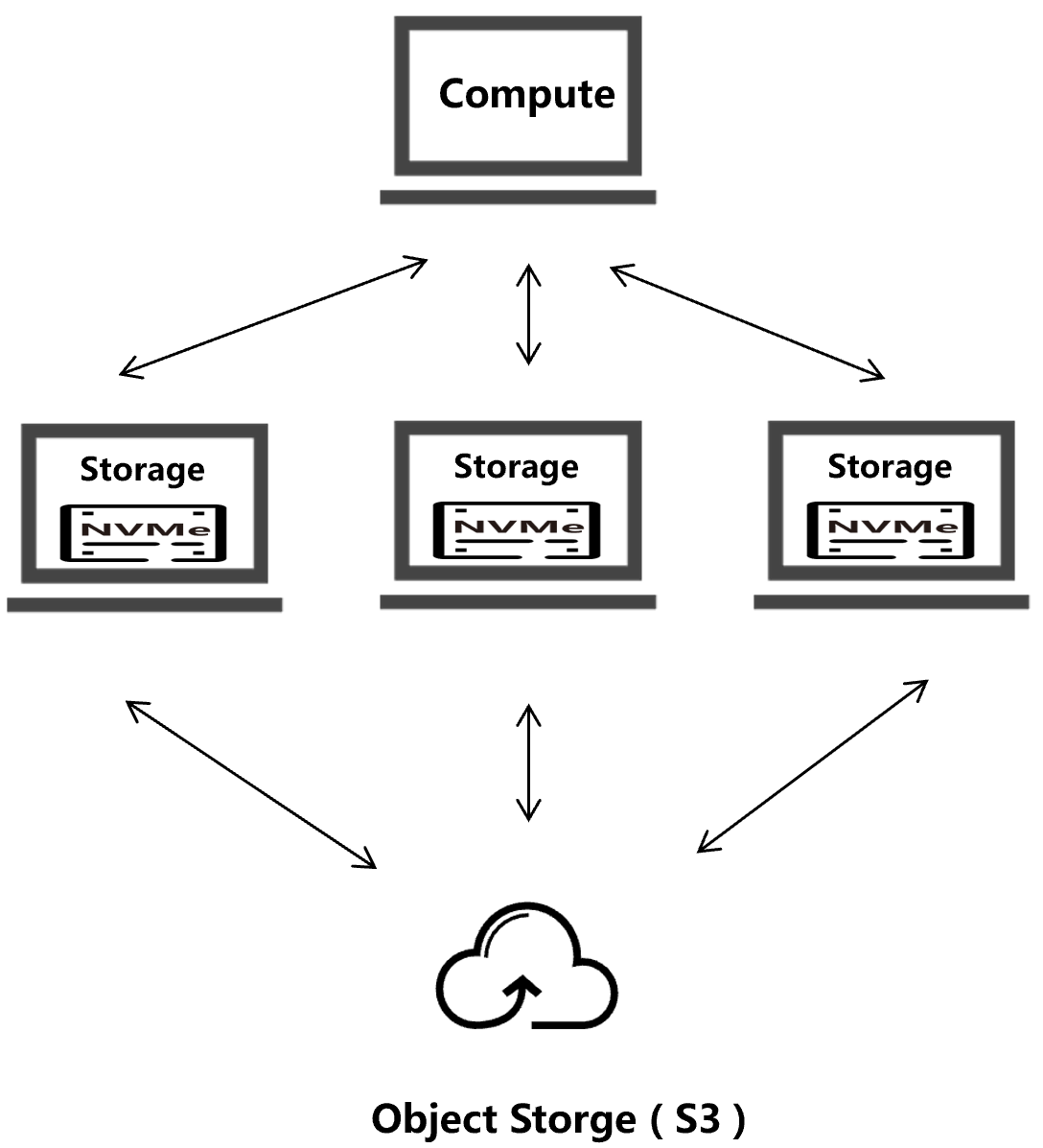
A key reason lies in the fixed resource ratios inherent to cloud instances. For example, on Amazon's storage-optimized i8g instances, each vCPU is paired with 8 GB of memory and 468 GB of local NVMe. While these CPU and memory resources are provisioned to handle cache-miss read requests, they often remain underutilized due to two factors: the intermittent nature of cache-miss reads depending on workload patterns, and the fact that accessing local NVMe may require much less CPU and memory than allocated.
Furthermore, this architecture introduces inherent inefficiencies. Each cache-miss read necessitates a network round trip, incurring not only additional latency but substantial CPU overhead on both ends for data serialization and network processing. The two-sided CPU cost of network-based access becomes an increasingly significant resource drain, making remote storage access less appealing compared to local NVMe operations.
Nevertheless, the original decoupling architecture maintains its relevance in some scenarios, e.g., when dealing with a large-scale dataset that they must be distributed across multiple storage nodes.
When dealing with large-scale datasets, we believe a more promising approach lies in horizontally scaling both compute nodes and their attached NVMe storage. This architecture avoids the resource overhead of the traditional decoupled model by transforming the entire system into a multi-writer distributed database, where compute, memory and storage resources are fully utilized for processing, not just for serving remote requests.
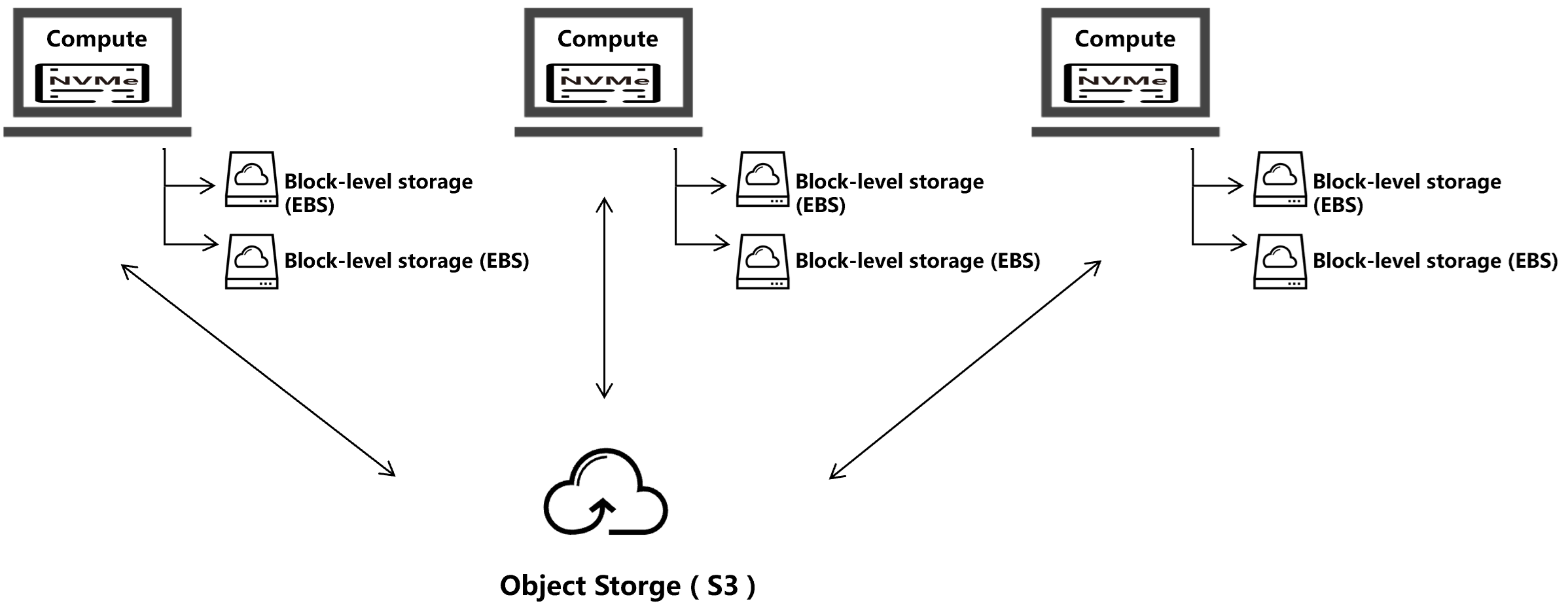
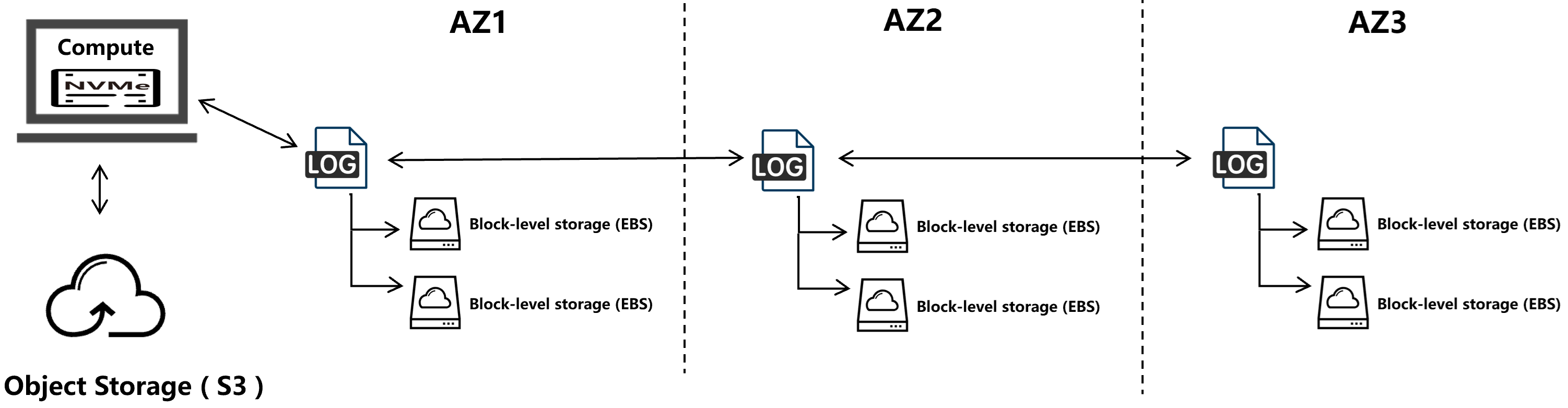
Viewing object storage as the decoupled persistence layer enables new variants of database architecture. This is evident in high availability designs: object storage natively provides cross-AZ or even cross-region reliability. By complementing this with replication of the transaction log across multiple zones, the entire database inherently achieves geo-distributed reliability. This approach eliminates the need for complex, resource-intensive storage nodes spanning multiple zones, replacing them with lightweight transaction log replicas that consume significantly fewer resources.
Conclusion
In this post, we re-examined the decoupled architecture of online databases through the lens of emerging cloud storage technologies, particularly the powerful combination of instance-level NVMe and object storage. We believe that this new storage paradigm is poised to become the new storage backbone for future cloud databases, ultimately reshaping how Database-as-a-Service (DBaaS) platforms are designed and deployed in the cloud.