Coroutines and Async Programming: The Future of Online Databases

Online databases are the backbone of interactive applications. Despite coming in many different types, online databases are all engineered for low-latency, high-throughput CRUD operations. At EloqData, we use the universal Data Substrate to build online databases for any model—from key-value and tables to JSON documents and vectors. In this post, we explore one of our core engineering practices for future online databases.
Hardware Trend
Database implementations are closely tied to hardware development. If we look back at the past decade, the trend is clear: the performance improvement of I/O devices has far outpaced that of CPUs. And the trend is likely to continue for the foreseeable future. As of 2025, it’s common for a single NVMe device to deliver 2 million IOPS. With 6 to 8 PCIE lanes, a single server can achieve a staggering total of 12 to 16 million IOPS.
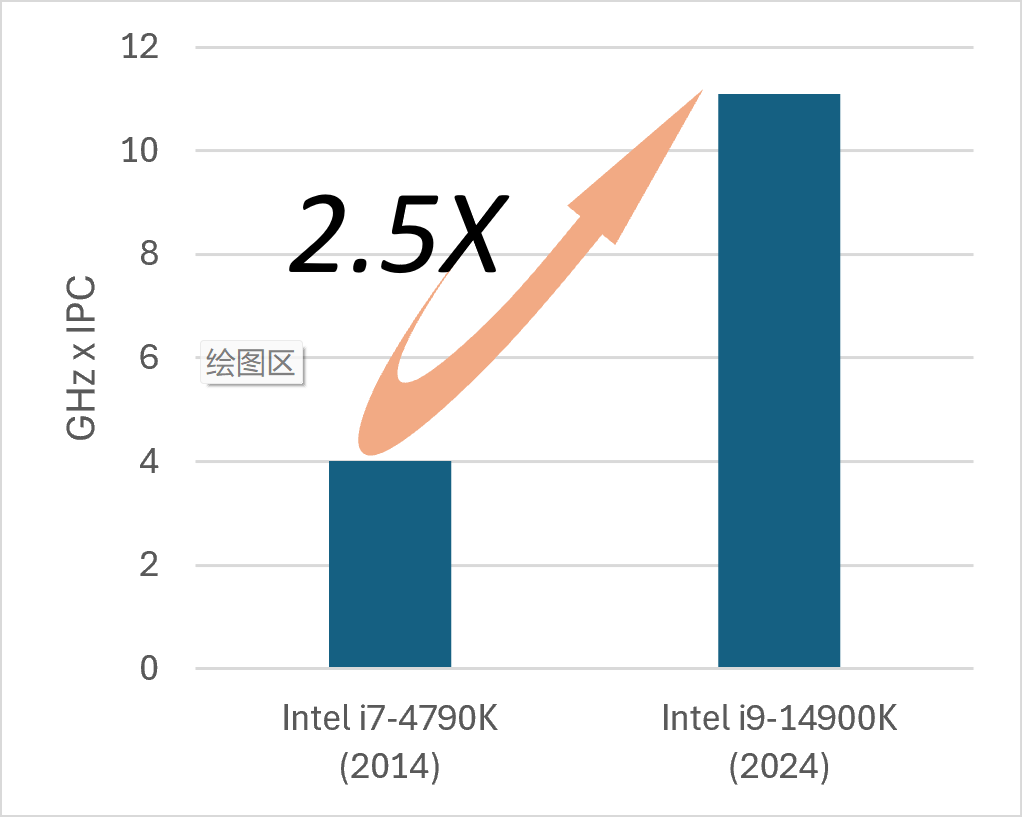
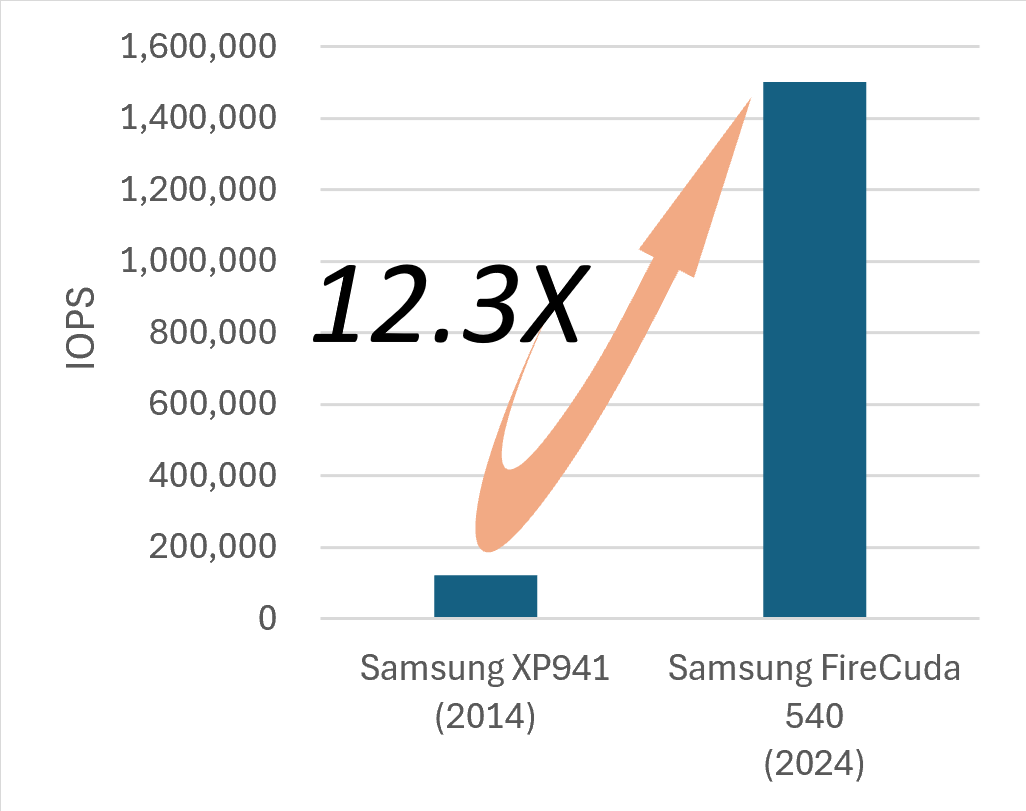
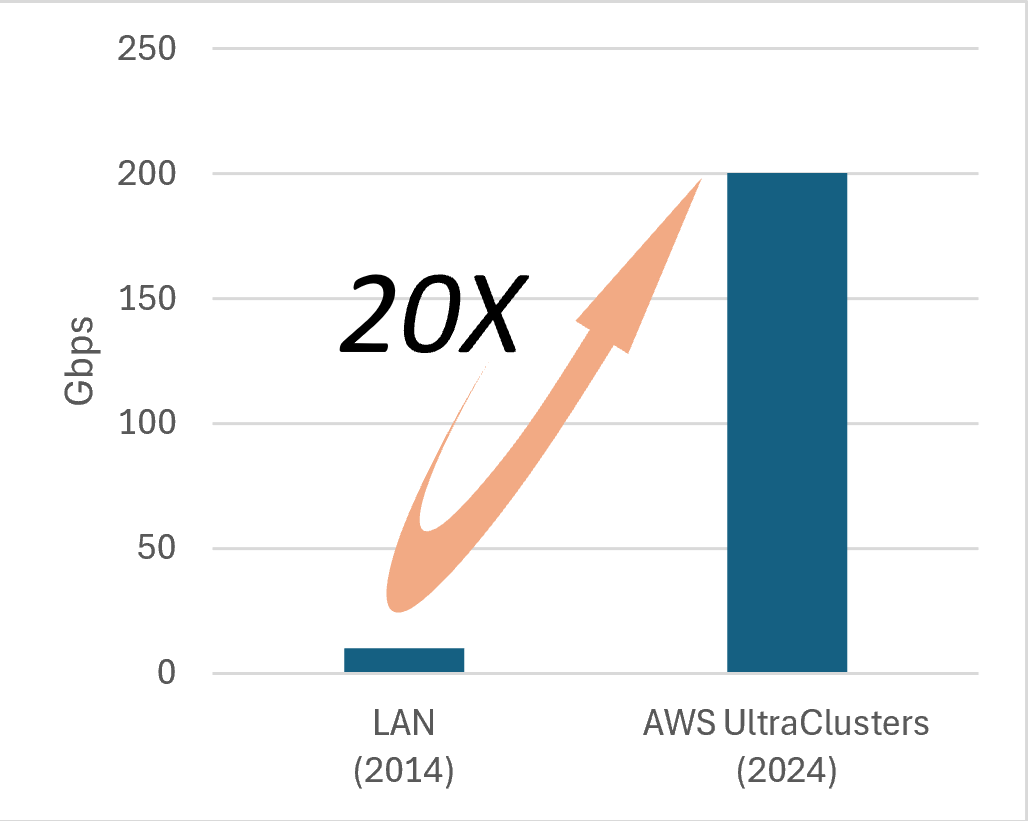
Such massive I/O gains, however, come at a cost. These staggering numbers can only be unlocked through massive parallelism. In the traditional multi-threading model, this means a proliferation of threads—each dispatching and waiting for an I/O request. In conventional engineering, dispatching an I/O request involves a synchronous syscall (e.g., read() or write()), and waiting for it incurs two context switches. Though these operations are fast in isolation, their aggregate CPU cost is significant in comparison to the needs of sustaining 16 million I/O operations per second.
What’s more, I/O requests don't appear out of thin air. In a database, every query initiates I/O requests and the average number of I/O requests per query remains relatively stable for a given workload. Pushing for greater I/O parallelism means handling more concurrent queries, which consumes additional CPU for query parsing and execution. The system quickly gets caught in a self-reinforcing downward spiral: escalating competition for CPU ultimately makes the database CPU-bound. Therefore, reducing the CPU cost, both for I/O and other core components, will be a primary focus for future database engineering.
Coroutines and Async Programming
Coroutines are functions that can be suspended and resumed. Unlike threads, which require expensive OS context switches, suspending or resuming a coroutine (whether stackless or stackful) is a user-space operation and can complete in less than 10 nanoseconds. This represents a 10 to 100-fold performance advantage, making coroutines an ideal programming model for processing massive parallel I/O requests.
Coroutines can unlock their full potential when combined with modern asynchronous I/O interfaces like io_uring. Async I/O allows a coroutine to dispatch an I/O request without blocking or invoking a syscall. After issuing the request, the coroutine suspends itself, allowing another coroutine to take over and continue execution, until it dispatches an I/O request and yields.
The advantages of coroutines extend beyond I/O to concurrency control in databases. Online databases must handle lots of concurrent reads and writes while ensuring proper isolation and serialization. This often requires blocking certain operations when data conflicts occur and resuming them later. The pattern of frequent suspension and resumption makes database queries an ideal use case for coroutines.
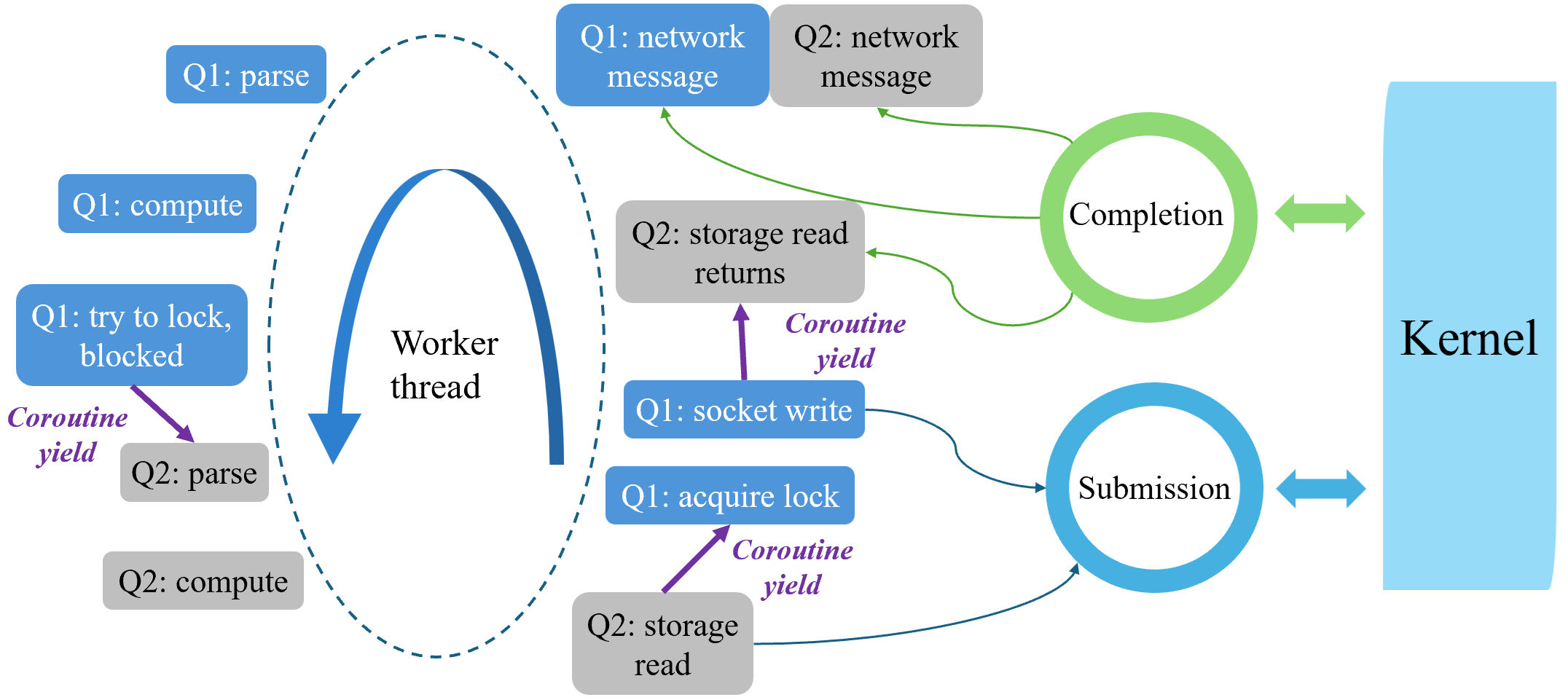
Combing coroutines and async I/O, we run each database query as a coroutine bound to a CPU core. Each core has a dedicated worker thread that runs an event loop. When new network messages arrive, the async I/O notifies the worker thread, which creates a coroutine for each query and processes them sequentially. Whenever query execution is blocked—whether due to concurrency control or waiting for storage/network access—the current coroutine yields, allowing the next coroutine in the line to run.
At the end of each loop iteration, the thread makes one syscall (io_uring_submit) to notify the kernel all pending I/O requests accumulated during that cycle. The worker thread also calls a second syscall (io_uring_peek_cqe) for completed I/O requests from prior iterations or new incoming network requests. Coroutines whose requests have returned are scheduled to resume in the next loop iteration.
Engineering Considerations
Coroutines are an old concept, but they have only recently gained popularity and achieved standardization in major programming languages. Throughout history, coroutines have appeared in various forms, such as
- Handwritten state machines for specific applications.
- Coroutines in programming frameworks, e.g., bthread in brpc.
- Stateful coroutines libraries, e.g., boost:context.
- Stackless coroutines libraries, e.g., std::generator.
These coroutine variants emerged at different times and vary widely in maturity. For instance, std::generator was only introduced in C++23 and lacked compiler support until the recent GCC 14 release. Databases are built over many years, spanning multiple language standard and compiler release cycles. At every stage of development, we must carefully evaluate the availability, maturity, and inherent trade-offs of each coroutine implementation. Our implementation as of today has used all the first three forms:
- Handwritten state machines for core transaction processing
- bthread in brpc for networking
- boost::context to transform third-party code of query processing into stackful coroutines
We’ve recently started adopting std::generator in some parts of transaction processing, where coroutine call chains are isolated and yield/resume states are complex to manage.
A second consideration when using coroutines is that they are susceptible to blocking: if a coroutine is blocked during execution, the entire worker thread is blocked. All other coroutines bound to that thread are also unable to make progress.
Blocking can arise from several sources. The first is I/O, which has been largely mitigated in our system through the adoption of async I/O. The second source is thread synchronization: when multiple worker threads access a critical section or a concurrent data structure, contention may cause one thread to block another. In our implementation, we adopt a shared-nothing memory architecture. Most thread synchronization is handled through lock-free concurrent queues. We still occasionally use locks (such as std::mutex), but we restrict them to very short, low-contention critical sections.
The third source of blocking originates from third-party code or libraries designed around the multi-threading model. Some code is straightforward to adapt. For instance, query processors, which involve minimal thread synchronization, require only minor code changes. Others, however, are inherently difficult or impossible to modify. One example is RocksDB, a widely used key-value store that serves as our default storage engine. As a multithreaded library, RocksDB relies extensively on internal locks and condition variables. Any coroutine invoking its APIs may block unpredictably. Hence, accessing RocksDB and similar libraries must be offloaded to a separate thread pool.
The final consideration is to carefully design internal states when using coroutines in distributed databases/systems. A key advantage of coroutines is their ability to preserve execution state—such as local variables and control flow—across suspension and resumption. However, this feature introduces a challenge in distributed environments, where failover is a common occurrence. Failover may not terminate the process but can invalidate node-local resources. Consider a scenario where a query holds a write lock, stores a pointer to it in its coroutine stack, and then yields. If a failover occurs during suspension, all locks on the node are deemed invalid. When the coroutine resumes, it must not blindly release the lock—which may now refer to an invalid memory address. To handle such cases, the system must incorporate a mechanism to validate coroutine-held resources that may be affected by failover. Only if the resources are confirmed to be alive should the resumed coroutine proceed to use them.
Conclusion
Coroutines and async programming represent a paradigm shift in building high-performance online databases for modern hardware. Their adoption, however, demands careful engineering and thoughtful design. Our journey has just begun, and we believe significant work remains to fully unlock their potential. One area is storage engines. Currently, very few are fully built on coroutines and async I/O. We anticipate this will change soon.