Breaking the Memory Barrier: Introducing EloqKV on EloqStore

Introduction
At CES 2026, NVIDIA CEO Jensen Huang delivered a stark warning: the industry is facing a critical shortage of DRAM. While the explosive growth of AI models is the primary driver, there is another massive consumer of memory that often flies under the radar: Caching Services.
Traditionally, caching services like Redis and Valkey are purely memory-based. Even though people have tried to leverage fast SSDs for caching (e.g. Apache KVRocks), for latency-sensitive workloads, DRAM-based solutions remained the only viable solution because SSD-based alternatives often have significant tail latency issues. In mission-critical environments, a latency spike can easily disrupt real-time workflows and render a service unresponsive. Until recently, how to tame tail latency for IO intensive workloads has remained an unsolved challenge.
Today, we're proud to introduce EloqKV powered by EloqStore. By leveraging the innovation of a modern data storage engine, EloqKV is the first Redis-compatible KV store designed to deliver DRAM-level P9999 latency with modern NVMe SSDs. By eliminating the performance tail that plagues traditional systems, EloqKV, when powered by EloqStore, offers up to 20X cost savings without sacrificing the millisecond-level latency your business demands.
As discussed in our previous blogs, EloqKV is not just a cache. It can work as a full persistent main data storage. In this blog, we re-examine the cache usage case and we will leave the full persistent evaluation in another post. In all our tests, we turn off the write ahead log (WAL) to relax the strong durability guarantee.
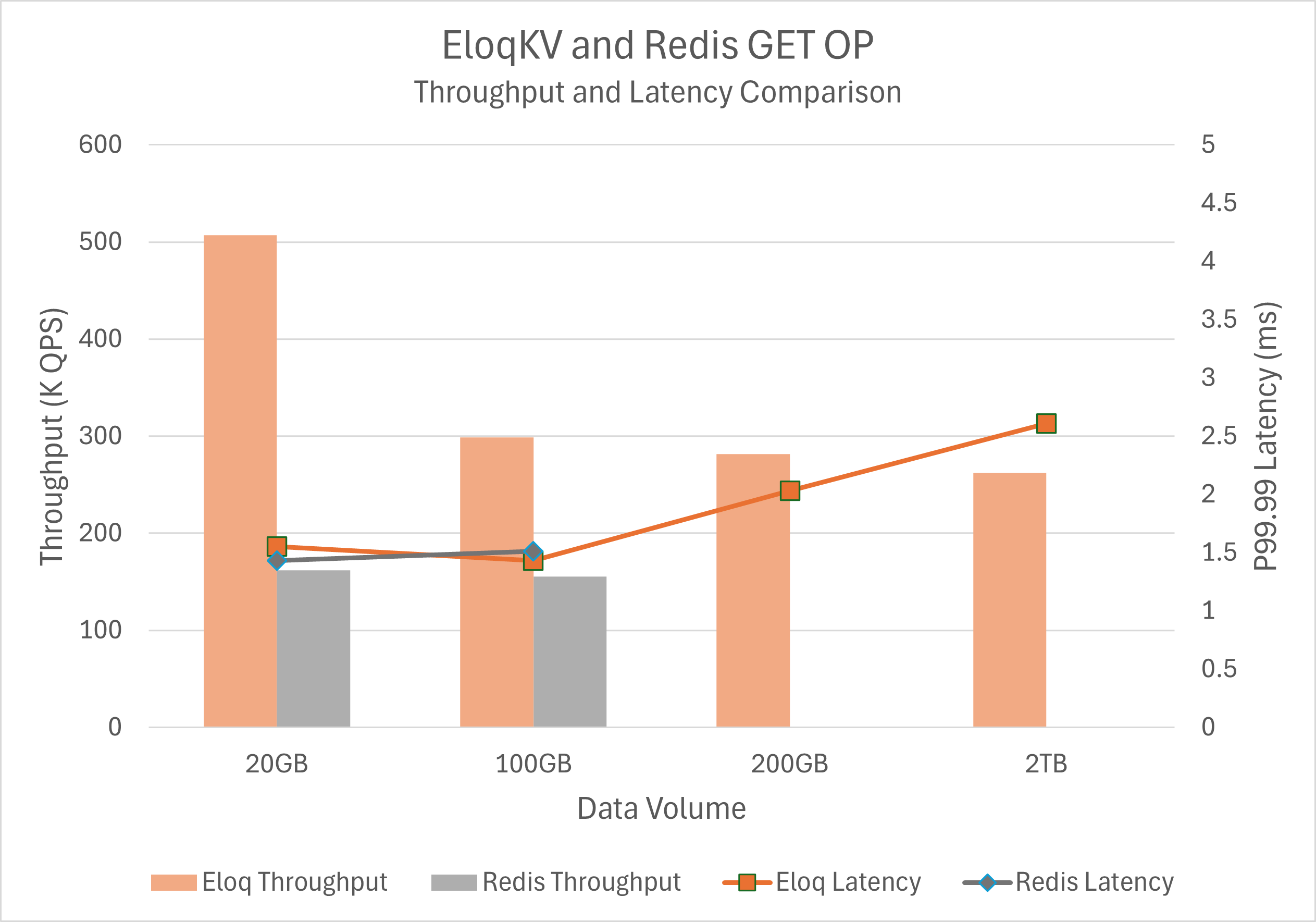
Traditional DRAM-based systems like Redis are strictly limited by physical memory capacity. As shown in the benchmark above, while Redis is restricted to smaller datasets, EloqKV breaks this barrier by leveraging NVMe without the "tail-latency penalty" typically associated with disks. In fact, at 20GB and 100GB, EloqKV actually provides higher throughput than Redis while maintaining a near identical P99.99 latency profile. When data size exceeds main memory size, Redis fails while EloqKV continues to scale. Even with a 2TB dataset, EloqKV maintains a stable P99.99 latency of a few milliseconds, a performance previously thought possible only in pure DRAM environments.
For comparison, we also tried KVRocks, a solution that supports SSD serving. As shown below, the P99.99 latency grows out of control as IO intensive operations interfere with the read latencies (notice the log scale).
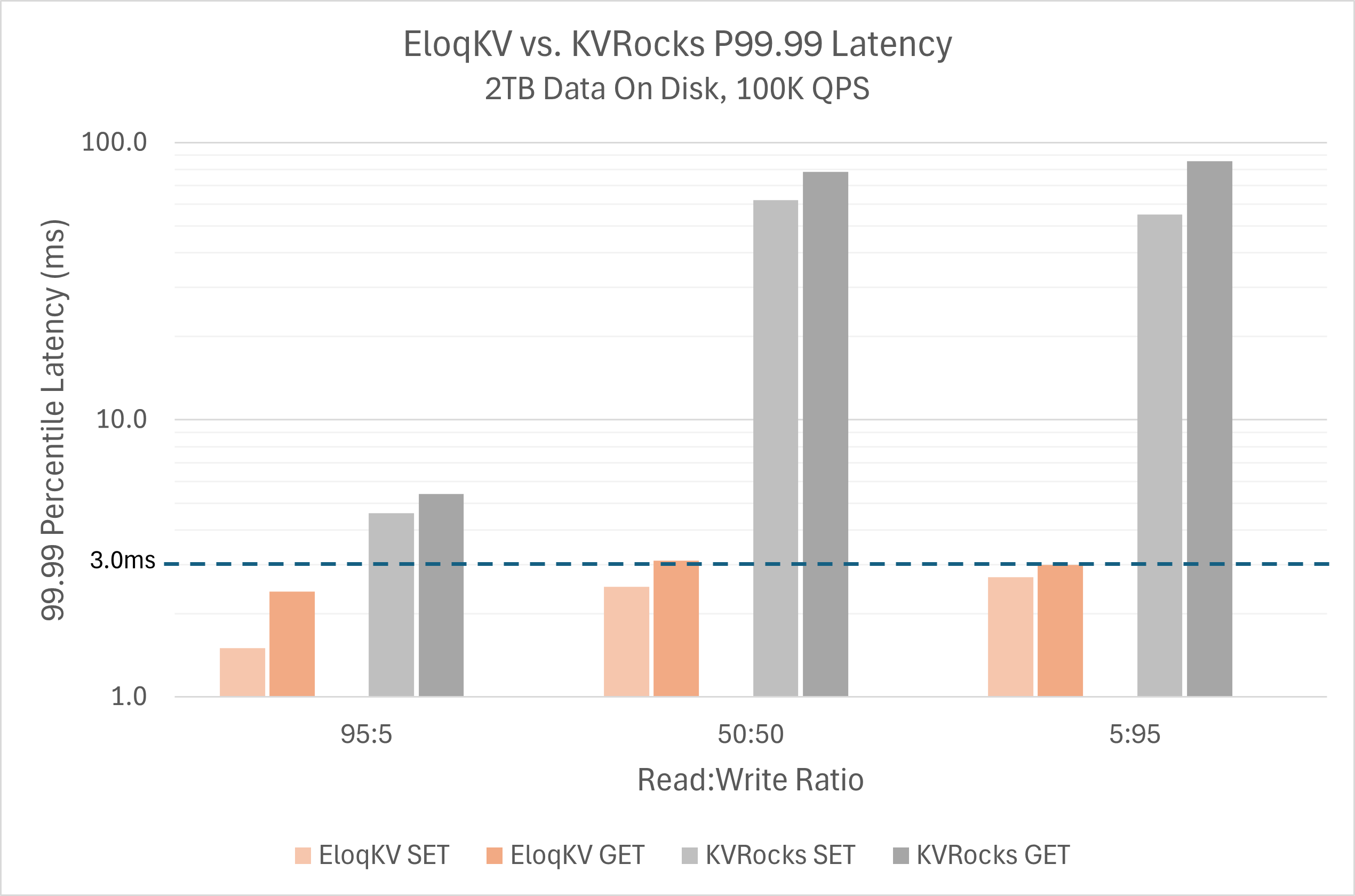
For full disclosure, here is the benchmark setup:
- Hardware: Single Node, GCP Z3-16 instance.
- Specs: 16 vCore, 128GB RAM, 2.9TB NVMe SSD x 2.
- Payload: Up to 800 Million KV pairs with variable payload sizes of 1-4KB.
- Benchmark Tool:
memtier_benchmark
By solving the P99.99 latency problem on SSDs, EloqKV allows businesses to scale their data footprint by orders of magnitude without sacrificing the sub-millisecond responsiveness their users demand. To manage a 2TB dataset with Redis, an organization would typically need a cluster of 20 nodes to provide enough RAM. EloqKV delivers the same "long-tail" latency reliably on a single NVMe-optimized node, slashing infrastructure costs by 20X.
The Long Tail Problem: Why SSD Caching is Hard
At the upcoming Unlocked Conference 2026, engineers from Uber will present "Real-world cache lessons from 1B RPS in prod." This highlights the scale modern infrastructure must handle. While a standard PostgreSQL or MySQL setup works fine for low throughput workloads and moderate-sized hot datasets, it crumbles under the "Internet Scale" traffic processed by Google, Amazon, Uber, and Snap.
The challenge is compounding in the AI Age. We are moving toward a future of Agent-to-Agent communication, which will generate 100x more data and RPS than human interaction. We see this with our own customers: AI chat scenarios create massive data explosion because prompts are long, complex, and carry context payloads 100x larger than typical human chat messages.
Since DRAM is expensive, the obvious alternative is to use SSDs. However, for high-performance caching, standard SSD implementations have historically failed. The dealbreaker isn't average latency, instead, it's the long tail latency, especially when dealing with millions or billions of requests per second (RPS). When you throw this level of concurrency at a standard SSD-based database, traditional architectures fail. Relying on multi-threading and synchronous I/O simply cannot guarantee consistent low tail latency on commodity hardware. The threads block, the context switches pile up, and the tail latency spikes.
The Software-Hardware Gap
Our research found that the issue with the unstable performance of current storage design is that the software stack, traditionally designed for hard-disk based storage systems, has not caught up with the times. Traditionally, disk is slow, and every effort should be made to increase the performance of disks. However, modern NVMe SSDs are incredibly fast, capable of delivering millions of IOPS and gigabytes per second throughput, even for random data accesses. To take advantage of such high performance disks, a few things need to be changed.
The first and most fundamental change is the overall database architecture, which we described in detail in our previous blog posts. In this blog, we discuss several implementation issues that allow us to fully exploit modern storage devices. In addition, two specific implementation techniques are also essential:
- Coroutines: To handle massive concurrency without the overhead of OS threads.
- io_uring: The Linux kernel interface that enables high-performance asynchronous I/O.
By combining these, we bypass the limitations of synchronous I/O. You can read more about our engineering philosophy on this topic in our deep dive: Coroutines & Async Programming.
Introducing Our Open Source EloqStore Engine
We developed EloqStore, a modern storage engine that is optimized for and takes advantage of the Data Substrate architecture to achieve unparalleled performance and stability. We are thrilled to announce that it is now Open Source.
EloqData's Data Substrate technology is designed for plugable storage engines. Previously, EloqKV utilized RocksDB and RocksCloud as its main underlying storage engine. While robust, RocksDB relies on Log-Structured Merge-trees (LSM), which suffer from well-known issues that destabilize long tail latency:
- Write Amplification: Repeatedly rewriting data during compaction.
- Read Amplification: Checking multiple files to find a single key.
- Compaction Stalls: CPU spikes during background compaction tasks.
EloqStore addresses these issues head-on by abandoning the traditional Log-Structured Merge-tree (LSM) architecture in favor of a design optimized specifically for the high-parallelism nature of modern NVMe SSDs. While LSM-trees are designed to sequentialize writes for older spinning disks, EloqStore is built from the ground up to exploit the random-access strengths and massive IOPS of modern flash storage.
Deterministic Performance via B-tree Variant Indexing
To achieve deterministic performance, EloqStore utilizes a specialized B-tree variant indexing strategy. It maintains a compact, memory-resident mapping of all non-leaf nodes, ensuring that the internal path to any piece of data is always held in DRAM.
This architecture guarantees exactly one disk access per read. By bypassing the multiple "level checks" found in RocksDB, EloqStore eliminates the read amplification that typically causes latency spikes during heavy lookups. Whether your dataset is 100GB or 10TB, a read request is always a direct, single-IOPS operation, providing the predictable latency required for mission-critical caching.
High-Throughput Batch Write Optimization
The write path is equally optimized through Batch Write Optimization. Leveraging io_uring, EloqStore bypasses the overhead of traditional synchronous system calls, allowing the engine to group multiple incoming writes into large, aligned blocks. This approach:
-
Reduces the frequency of expensive disk commits.
-
Significantly lowers write amplification.
-
Preserves the lifespan of the SSD while maintaining massive throughput.
Coroutines and Async I/O
Under the hood, EloqStore is built with coroutines. This allows the system to handle thousands of concurrent requests without the heavy memory footprint or context-switching penalties of OS threads. When an I/O operation is pending, the coroutine simply yields, allowing the CPU to process other requests until the NVMe signals completion via io_uring. Coroutine-based language-level concurrency and kernel-level asynchronous I/O allow EloqKV to maintain sub-millisecond responsiveness under heavy load.
Eliminating the "Compaction Stall"
Most importantly, this architecture eliminates the jitter caused by background maintenance. Traditional LSM-trees must periodically merge and rewrite files to maintain performance—a process that consumes massive CPU and I/O resources, leading to the dreaded "compaction stall." EloqStore's append-only design manages data reclamation more gracefully, ensuring that background tasks never interfere with foreground traffic. The result is a P9999 latency profile that stays flat, delivering a "memory-like" experience at disk-based economics.
Rethinking the Key-Value Store for the AI Era
Beyond its performance as a cache, EloqKV is a full-featured key-value store. This architectural shift enables a new class of advanced features:
-
Cloud-Native "Scale to Zero": Because data is persisted on NVMe and/or object storage rather than volatile DRAM, EloqKV can spin down to zero when idle.
-
AI-Native "Quick Branching": For complex AI workflows and agent simulations, EloqKV supports rapid branching. You can fork your state to explore different prompt chains or agentic outcomes without duplicating massive DRAM footprints.
-
Automatic Archiving: Archiving is no longer a separate operation and you do not need to choose a "cut-off" period. EloqKV does not even require you to have sufficient capacity to store all your data on local SSD. In fact, cold data can be seamlessly and automatically tiered to low-cost object storage such as S3. The only penalty is a few seconds of delay when accessing cold data.
Meet us at Unlocked 2026
We are excited to announce that EloqData is a sponsor of the Unlocked Conference 2026, hosted by Momento and AWS.
Unlocked is the premier event for developers discussing the future of backend infrastructure. We are eager to discuss how the shift from DRAM to NVMe can unlock new possibilities for AI and hyperscale applications.
Come visit our booth, chat with our engineers, and see EloqStore in action. We look forward to seeing you there.